Lingvistik är vetenskapen som studerar språk
Lingvistik. Faktum är att vi faktiskt står inför detta vetenskapsområde nästan från första klass när vi börjar studera ...
COVARIATION-funktionen i Excel beräknar kovarianskoefficienten för två datamängder (matriser eller cellområden som lagrar numeriska värden) som är exempel på motsvarande dataområden och returnerar motsvarande numeriska värde.
COVARIATION.G-funktionen i Excel används för att beräkna kovarianskoefficienten för hela populationen med två dataområden (population) och returnerar motsvarande värde.
KOVAR-funktionen i Excel är utformad för att beräkna kovarianskoefficienten för två uppsättningar numeriska data som är populationer.
Excel-kalkylbladet innehåller två intervall med data, varav den första kännetecknar antalet böcker som läses per år av varje elev som väljs från flera skolor och den andra karakteriserar slutbetyget i litteraturen på en 10-punktsskala. Bestäm kovarianskoefficienten för de två dataområdena.
Källtabellvy:
Eftersom flera studenter av olika betyg valdes för analys kan båda intervallen betraktas som prover från den allmänna befolkningen, som inkluderar alla 9: e klassstudenter i en viss skola. Vi använder följande funktion:

Beskrivning av argument:
Resultatet är:

Det resulterande värdet indikerar närvaron av en direkt relation mellan värdena från de två områdena. Det vill säga det kan antas att en student som läser fler böcker får högre betyg för ämnet.
Excel-kalkylbladet innehåller data om tillväxten (positivt antal) eller prisfall (negativt) för två olika värdepapper under 12 månader av året i förhållande till något initialvärde. Bestäm kovariansen mellan de två dataområdena och dra slutsatser. Gör rapporten tillgänglig för Excel 2007-användare.
Källtabellvy:

I detta exempel undersöks hela det allmänna urvalet. Du kan använda COVARIATION.G-funktionen för beräkningen, men resultaten kommer inte att vara tillgängliga för användare av äldre versioner av Excel. Låt oss tillämpa följande formel:

Som ett resultat får vi:

Detta värde indikerar ett ganska stort samband mellan de studerade värdena. Eftersom siffran är negativ vänds detta förhållande. Det vill säga när priset på en aktie stiger faller priset på den andra och vice versa. Det kan antas att dessa aktier ägs av två konkurrerande företag.
Excel-tabellen innehåller uppgifter om efterfrågan på alkoholhaltiga drycker, prisindexet och inkomstnivån för befolkningen i staten. Analysera sambandet mellan tillgängliga data.
Vy över den ursprungliga datatabellen:

Först beräknar vi kovariansen mellan efterfrågan och prisindexet med formeln:

Resultatet är:

För att bedöma graden av förhållande mellan två dataområden är det bekvämare att använda korrelationskoefficienten, som kan beräknas utan att använda CORREL-funktionen på följande sätt:
B12 / ROOT (DISP.Y (B3: B10) * DISP.Y (C3: C10))
Funktionen DISP.G används för att beräkna variationen i befolkningen. Ovanstående formel visar tydligt förhållandet mellan koefficienterna för kovarians och korrelation.
Resultatet är:

Som du kan se finns det ett ganska starkt omvänt förhållande mellan priser och efterfrågan. För att bestämma graden av efterfrågan påverkar vi dock bestämningskoefficienten r2 med formeln:
GRAD (B13; 2)
Det resulterande värdet, uttryckt i procent:

Det vill säga cirka 59% av variationen i efterfrågan under studietiden beror på prisvolatilitet. De återstående 41% är andra faktorer. Och en annan faktor i detta exempel är inkomstnivån. Låt oss beräkna korrelationskoefficienten mellan efterfrågan och inkomst med hjälp av följande funktion:
KORREL (B3: B10; D3: D10)
Resultat:

Ett positivt värde på 0,741 motsvarar ett ganska starkt samband mellan inkomsttillväxt och efterfrågan. För att bestämma den totala korrelationskoefficienten och dra slutsatser hittar vi korrelationskoefficienten mellan prisindex och inkomstnivå:
KORREL (C3: C10; D3: D10)
Resultat:

Vi har ett inte särskilt uttalat omvänt förhållande. Låt oss nu beräkna den totala korrelationskoefficienten med hjälp av formeln:
\u003d (B13-B15 * B16) / ROOT ((1-GRAD (B15,2)) * (1-GRAD (B16,2)))
Resultat:

Beräkningar visar att effekterna av stigande priser på efterfrågan är "utjämnade" på grund av en ökning av hushållens inkomst. Kvadratroten av den senare modulvärdet är ungefär 91%, vilket visar hur mycket variationen i priser bestämde variationen i efterfrågan på alkoholhaltiga drycker, exklusive den parallella variationen i inkomst.
KOVAR-funktionen har följande syntax:
KOVAR (array1, array2)
COVARIATION.-funktionen har följande syntax:
COVARIATION.In (array1, array2)
Syntaxen för COVARIATION.G-funktionen är:
COVARIATION.G (array1, array2)
Alla betraktade funktioner tar följande argument som inmatning:
Anmärkningar 1:
Anmärkningar 2:
Anmärkningar 3:
När det gäller en flerdimensionell slumpmässig variabel (slumpmässig vektor) är kännetecknet för spridningen av dess komponenter och förhållandet mellan dem kovariansmatrisen.
Kovariansmatris definieras som den matematiska förväntningen på produkten av en centrerad slumpmässig vektor med samma men transponerade vektor:
var 
Kovariansmatrisen har formen

där på diagonalen är variationerna i koordinaterna för den slumpmässiga vektorn o n \u003d D Xi, o 22 \u003d D X2, о кк = D Xk, och resten av elementen är kovariansen mellan koordinaterna
° 12 \u003d M "x i x 2 j a 1 * \u003d M-jc, **\u003e
Kovariansmatrisen är en symmetrisk matris, dvs. ![]()
Tänk till exempel på kovariansmatrisen för en tvådimensionell vektor

Kovariansmatrisen erhålls på liknande sätt för alla / ^ -dimensionella vektorer.
Koordinatvariationer kan representeras som
där Gi, C2, ..., 0? är de genomsnittliga kvadratavvikelserna för koordinaterna för den slumpmässiga vektorn.
Som ni vet kallas korrelationskoefficienten förhållandet mellan kovarians och produkten av standardavvikelser:

Efter normalisering med det sista förhållandet mellan medlemmarna i kovariansmatrisen erhålls korrelationsmatrisen

vilket är symmetriskt och icke-negativt bestämt.
Den flerdimensionella analogen av variansen för en slumpmässig variabel är den generaliserade variansen, vilket förstås som värdet på determinanten för kovariansmatrisen
![]()
Ett annat vanligt kännetecken för spridningsgraden för en flerdimensionell slumpmässig variabel är spåret av kovariansmatrisen
där Ckk är diagonala element i kovariansmatrisen.
Normalfördelningen används ofta i multivariat statistisk analys.
En generalisering av den normala sannolikhetstätheten till fallet med en ^ -dimensionell slumpmässig vektor är funktionen
där q \u003d (pj, q 2, M ^) t - kolumnvektor med matematiska förväntningar;
| X | - determinant för kovariansmatrisen X;
1 - invers kovariansmatris.
Matris X -1 invers till matris X för dimension nx n, kan erhållas på olika sätt. En av dem är Jordan-Gauss-metoden. I det här fallet sammanställs matrisekvationen
var x - vektorkolumn av variabler, vars antal är lika med i; b - i-dimensionell kolumnvektor på höger sida.
Låt oss multiplicera ekvation (6.21) till vänster med den inversa matrisen XY 1:
![]()
Eftersom produkten av den inversa och den givna matrisen ger identitetsmatrisen E, sedan
![]()
Om istället för b ta enhetsvektor

därefter produkten X-1 -e x ger den första kolumnen i den inversa matrisen. Om vi \u200b\u200btar den andra enhetsvektorn

sedan produkten E 1 e 2 ger den första kolumnen i den inversa matrisen, etc. Således successivt lösa ekvationerna
![]()
enligt Jordan-Gauss-metoden får vi alla kolumner i den inversa matrisen.
En annan metod för att erhålla matrisen invers till matrisen E är relaterad till beräkning av algebraiska komplement A tJ .= (/= 1, 2,..., p; j \u003d 1, 2, ..., p) till elementen i denna matris E, ersätter dem istället för element i matrisen E och transporterar en sådan matris:

Den inversa matrisen erhålls efter uppdelning av elementen I till determinanten för matrisen E:
Ett viktigt särdrag för att erhålla den inversa matrisen i detta fall är att kovariansmatrisen E är svagt konditionerad. Detta leder till att när man inverterar sådana matriser kan ganska allvarliga fel uppstå. Allt detta kräver att man säkerställer nödvändig noggrannhet i beräkningen eller använder speciella metoder vid beräkning av sådana matriser.
Exempel. Skriv uttrycket för sannolikhetstätheten för en normalt fördelad tvådimensionell slumpmässig variabel (X v X 2)
förutsatt att de matematiska förväntningarna, avvikelserna och kovarianterna för dessa mängder har följande betydelser:
Beslut. Den inversa kovariansmatrisen för matris (6.19) kan erhållas med användning av följande uttryck för den inversa matrisen för matris X:

där A är determinanten för matrisen X.
A och, L 12, A 21, A 22 - algebraiska komplement till motsvarande element i matrisen X.
Sedan för matrisen] r-! vi får uttrycket

Eftersom a 12 \u003d 01О2Р och ° 2i \u003d a 2 a iP\u003e a a i2 a 2i \u003d cyfst | p betyder det att

Hitta arbetet


Sannolikhetsdensitetsfunktionen skrivs i formen

Genom att ersätta de ursprungliga uppgifterna får vi följande uttryck för sannolikhetsdensitetsfunktionen

Matematiskt kovarians (engelsk Kovarians) är ett mått linjärt förhållande två slumpmässiga variabler. I portföljteorin används denna indikator för att bestämma förhållandet mellan avkastningen på en viss säkerhet och avkastningen på en värdepappersportfölj. För att beräkna avkastningskovariansen, använd följande formel:
var k i - avkastningen av säkerheten under den första perioden,
Säkerhetens förväntade (genomsnittliga) avkastning;
p i - portföljavkastning under den första perioden,
Förväntad (genomsnittlig) portföljavkastning;
n - antalet observationer.
Det bör noteras att nämnaren med formeln är substituerad ( n-1), om kovariansen beräknas baserat på ett urval från den allmänna observationspopulationen. Om beräkningarna tar hänsyn till hela befolkningen, ersätts nämnaren n.
Exempel... Tabellen visar dynamiken i avkastningen på aktierna i bolag A och företag B samt dynamiken i avkastningen på värdepappersportföljen.

För att använda ovanstående formel för att beräkna avkastningskovariansen för varje aktie i en portfölj, måste du beräkna den genomsnittliga avkastningen, som kommer att vara:

Kovariansen mellan aktierna i bolag A och portföljen blir således -0,313 och aktierna i bolaget B - 0,242.
Cov (k A, k p) = ((5,93-4,986)(2,27-3,201) + (5,85-4,986)(2,39-3,201) + (5,21-4,986)(3,47-3,201) + (5,37-4,986)(3,21-3,201) + (4,99-4,986)(2,95-3,201) + (4,87-4,986)(2,97-3,201) + (4,70-4,986)(3,32-3,201) + (4,75-4,986)(3,65-3,201) + (4,33-4,986)(3,97-3,201) + (3,86-4,986)(3,81-3,201))/(10-1) = -0,313
Cov (k B, k p) = ((4,25-5,031)(2,27-3,201) + (4,47-5,031)(2,39-3,201) + (4,68-5,031)(3,47-3,201) + (4,71-5,031)(3,21-3,201) + (4,77-5,031)(2,95-3,201) + (5,25-5,031)(2,97-3,201) + (5,45-5,031)(3,32-3,201) + (5,33-5,031)(3,65-3,201) + (5,55-5,031)(3,97-3,201) + (5,85-5,031)(3,81-3,201))/(10-1) = 0,242
Liknande beräkningar kan göras i Microsoft Excel med funktionen COVARIATION.B för ett urval från den allmänna befolkningen eller COVARIATION.G-funktionen för hela befolkningen.
Värdet på kovarianskoefficienten kan vara antingen negativt eller positivt. Dess negativa värde indikerar att avkastningen på säkerheten och avkastningen på portföljen visar rörelse i flera riktningar. Med andra ord, om avkastningen på ett värdepapper stiger kommer avkastningen på portföljen att sjunka och vice versa. Ett positivt värde indikerar att avkastningen på värdepapperet och portföljen förändras i samma riktning.
Ett lågt värde (nära 0) av kovarianskoefficienten observeras när fluktuationer i värdepappersavkastningen och portföljens avkastning är slumpmässiga.
Låt oss överväga tekniken för att beräkna kovariansen och korrelationen av värdepappersräntor med hjälp av ett exempel.
Avkastningen på papper X under fem år var 20%, 25%, 22%, 28%, 24%. Utbyte på papper F: 24%, 28%, 25%, 27%, 23%. Bestäm avkastningen på värdepapper.
Låt oss presentera lösningen på problemet på två sätt.
a) Vi skriver ut i kronologisk ordning i celler med Al no A5 värdena för utbytet av papper X och i cellerna B1 till B5 - utbytet av papper F. Vi får lösningen i cell C1, så vi svävar över den och klicka med musen. Vi skriver formeln i cell C1:
och tryck på Enter. Lösningen på problemet uppträdde i cell C1 - figur 3.08, dvs. provkovarians för vårt exempel.
b) Kovarians kan beräknas med hjälp av "Funktionsguiden". För att göra detta, håll muspekaren över A-ikonen i verktygsfältet och klicka. Fönstret "Funktionsguide" visas. I det vänstra fältet ("Kategori") flyttar du markören över "Statistisk" -raden och klickar med musen. Linjen var markerad i blått, och en lista över statistiska funktioner dök upp i fönstrets högra fält ("Funktion"). Håll markören över raden "KOVAR" och klicka på vänster musknapp. Linjen är markerad i blått. Håll markören över OK-knappen och klicka med musen. Fönstret "KOVAR" dök upp. Det finns två rader i fönstret, som heter "Array 1" och "Array 2". I den första raden anger vi antalet celler från A1 till A5. För att göra detta, håll muspekaren över tecken 3, som finns med höger sida första raden och klicka med musen. Fönstret "KOVAR" har blivit fältet för första raden. Håll muspekaren över cell A1, tryck på vänster musknapp och håll den intryckt, flytta markören ner till cell A5 och släpp knappen. Posten A1: A5 dök upp i radfältet. Håll muspekaren över ??? och klicka med musen. Det utökade fönstret "KOVAR" dök upp. Vi anger antalet celler från Bl till B5 i andra raden. För att göra detta, flytta markören över 5J-tecknet i andra raden och klicka med musen. Håll markören över cell B1, tryck på vänster musknapp och håll den intryckt, flytta markören ned till cell B5, släpp knappen. Posten B1: B5 dök upp i radfältet. Håll muspekaren över knappen 3 | och klicka med musen. Det utökade fönstret "KOVAR" dök upp. Håll markören över OK-knappen och klicka med musen. Siffran 3.08 dök upp i cell C1.
Bestäm korrelationskoefficienten för värdepappersavkastningar för villkoren i exempel 1. Lösning. Låt oss presentera lösningen på problemet på två sätt.
a) Vi skriver ut i kronologisk ordning i celler med Al no A5 värdena för utbytet av papper X och i cellerna B1 till B5 - utbytet av papper F. Vi får lösningen i cell C1, så vi svävar över den och klicka med musen. Vi skriver formeln i cell C1:
![]()
och tryck på Enter. Lösningen på problemet uppträdde i cell C1 - siffran 0,612114.
b) Korrelationen kan beräknas med programmet "Funktionsguide". För att göra detta, välj ikonen "l" i verktygsfältet med markören och klicka. Fönstret "Funktionsguide" visas. I det vänstra fältet ("Kategori") väljer du "Statistisk" rad med markören och klickar med musen. En lista över statistiska funktioner har dykt upp i fönstrets högra fält ("Funktion"). Välj raden "CORREL" med markören och klicka med musen. Linjen är markerad i blått. Håll markören över OK-knappen och klicka med musen. Fönstret "CORREL" dök upp. Det finns två rader i fönstret, som heter "Array 1" och "Array 2". I den första raden anger vi antalet celler med Al no A5. För att göra detta, flytta markören över ZR-tecknet till höger om den första raden och klicka med musen. CORREL-fönstret har blivit det första radfältet. Håll muspekaren över cell A1, tryck på vänster musknapp och håll den intryckt, flytta markören ner till cell A5 och släpp knappen. Posten A1: A5 dök upp i radfältet. Håll markören över U-tecknet igen och klicka på musen. Det utökade fönstret "CORREL" dök upp. Vi anger antalet celler från Bl till B5 i andra raden. För att göra detta, flytta markören över W-tecknet i andra raden och klicka med musen. Håll markören över cell B1, tryck på vänster musknapp och håll den intryckt, flytta markören ned till cell B5, släpp knappen. Posten B1: B5 dök upp i radfältet. Håll markören över Sh-knappen och klicka. Det utökade fönstret "CORREL" dök upp. Håll markören över OK-knappen och klicka med musen. Siffran 0.612114 uppträdde i cell Cl.
I exempel 1 och 2 beräknade vi kovariansen och korrelationen för avkastningen för de två värdepappren i portföljen. Om portföljen innehåller ett större antal värdepapper kan kovarianterna och korrelationerna av deras avkastning beräknas parvis som beskrivs ovan, men detta är en mödosam lösning på problemet. Excel har ett specialpaket "Data Analysis", som gör att du snabbt kan lösa detta problem för ett stort antal papper. Låt oss överväga beräkningen av kovarians och korrelationer med den.
Vet du att: Forexmäklare "NPBFX" tar absolut alla sina kunders transaktioner till likviditetsleverantörer (på interbankmarknaden), som arbetar med sTP / NDD-teknik (Straight-through-behandling - end-to-end transaktionsbehandling / Non Dealing Desk).


Analyspaketet kanske inte installeras. Då måste den installeras. För att göra detta, håll muspekaren över menyn "Service" och klicka på vänster musknapp. En rullgardinsmeny har dykt upp. Välj kommandot "Tillägg" med markören och klicka på vänster musknapp. Dialogrutan Tillägg visas. Håll markören över fönstret till vänster om raden "Analyspaket" och klicka på vänster musknapp. En bock (bock) dök upp i fönstret. Håll markören över OK-knappen och klicka med musen. "Analyspaketet" är installerat. Låt oss överväga definitionen av kovarians och korrelationer för flera värdepapper med hjälp av ett exempel.
Exempel 3. Beräkning av kovarians
Det finns ett urval av data om avkastningen på värdepapper B, C och D under tio perioder. Vi skriver ut avkastningsvärdena för papper B i celler från B1 till B10, papper C från C1 till CU och papper D från D1 till D10, som visas i fig. 1.8. Håll markören över menyn "Service" och klicka på vänster musknapp. En rullgardinsmeny har dykt upp. Håll markören över raden "Dataanalys" och klicka på vänster musknapp. Fönstret Dataanalys visas. Håll markören över raden "Kovarians" och klicka på vänster musknapp. Linjen är markerad i blått. Håll markören över OK-knappen och klicka med musen. Fönstret "Kovarians" har dykt upp (se bild 1.10).


Håll markören över tecknet 3 till höger om raden "Inmatningsintervall" och klicka med musen. Covariance-fönstret har kollapsat i ett radfält. Håll markören över cell B1, tryck på vänster musknapp och håll ned den, dra den till cell D10. Posten $ B $ 1: $ D $ 10 dök upp på linjen. Håll markören över tecknet igen och klicka. Det utökade kovariansfönstret visas. Vi grupperar data efter kolumner. Därför, om det inte finns någon punkt i det runda fönstret till vänster om etiketten "efter kolumner", flyttar du markören över den och klickar på vänster musknapp. En punkt visas i fönstret. Nedan visas raden "Outputinterval". Det ska finnas en prick i det runda fönstret till vänster om etiketten. Om den inte finns där flyttar du markören över den här raden och klickar på vänster musknapp. En punkt visas i fönstret. Håll markören över 3 till höger om fältet "Outputintervall" och klicka med musen. Covariance-fönstret har blivit ett strängfält. Ta cell A12 som början på utgångsintervallet. Därför flyttar vi markören över den och trycker på vänster musknapp. Posten $ A $ 12 dök upp i radfältet. Håll markören över tecken 3 igen och klicka med musen. Covariance-fönstret har expanderat. Håll markören över OK-knappen och klicka med musen. Lösningen på problemet uppträdde på arket som visas i fig. 1.11. Blocket från B13 till D15 presenterar kovariansmatrisen. På sin diagonala, dvs. i cellerna B13, C14 och B15 är avvikelserna för värdepapper B, C respektive D i de återstående cellerna - kovariansen av värdepappersavkastningen: i cell B14, kovariansen av avkastningen av värdepapper B och C, i B15 - värdepapper B och D, i C15 - värdepapper C och D ...

Exempel 4. Beräkning av korrelationer
Det finns ett urval av data om avkastningen på tre värdepapper - B, C och D - under tio perioder. Som i uppgift 3 skriver vi ut avkastningsvärdena för papper B i celler från B1 till B10, papper C från C1 till C10 och papper D från D1 till D10 (fig 1.9). Håll markören över menyn "Service" och klicka på vänster musknapp. En rullgardinsmeny har dykt upp. Håll markören över raden "Dataanalys" och klicka på vänster musknapp. Fönstret Dataanalys visas. Håll markören över raden "Korrelation" och klicka på vänster musknapp. Linjen är markerad i blått. Håll markören över OK-knappen och klicka. Korrelationsfönstret har dykt upp (det har samma struktur som "kovarians" -fönstret). Håll markören över tecknet 3 till höger om raden "Inmatningsintervall" och klicka med musen. Korrelationsfönstret har kollapsat i radfältet. Håll markören över cell B1, tryck på vänster musknapp och håll den intryckt, flytta markören till cell D10. Posten $ B $ 1: $ D $ 10 dök upp på linjen. Håll markören över tecknet igen och klicka. Det utökade fönstret "Korrelation" visas. Vi grupperar data efter kolumner. Därför, om det inte finns någon punkt i det runda fönstret till vänster om inskriptionen "efter kolumner", flyttar du markören över den och klickar på vänster musknapp. En punkt visas i fönstret. Nedan visas raden "Outputinterval". Det ska finnas en prick i det runda fönstret till vänster om etiketten. Om den inte finns där flyttar du markören över den här raden och klickar på vänster musknapp. En punkt visas i fönstret. Håll markören över 3 till höger om radfältet "Outputinterval" och klicka med musen. Korrelationsfönstret har blivit en radruta. Ta cell A12 som början på utgångsintervallet. Därför flyttar vi markören över den och trycker på vänster musknapp. Posten $ A $ 12 dök upp i radfältet. Håll markören över tecken 3 igen och klicka med musen. Korrelationsfönstret expanderar. Håll markören över OK-knappen och klicka. Lösningen på problemet uppträdde på arket som visas i figur 1.12. I blocket från B13 till D15 presenteras korrelationsmatrisen. På sin diagonala, dvs. i cellerna B13, C14 och D15 finns det enheter, i de återstående cellerna finns korrelationer av avkastningen på värdepapper: i cell B14 är korrelationen mellan avkastningen på värdepapper B och C, i B15 - värdepapper B och D, i C15 - värdepapper C och D.

Innehåll

Lingvistik. Faktum är att vi faktiskt står inför detta vetenskapsområde nästan från första klass när vi börjar studera ...

1700-talet anses vara århundradet med den stora franska revolutionen. Monarkiets störtande, revolutionära rörelser och levande exempel ...
Inledning 1. Typer av enzymer 2. Struktur av enzymer Enzymers verkningsmekanism Bibliografisk lista Inledning Enzymer -...

Cosimo Medici (1389-1464), den äldste sonen till bankiren Giovanni de Bicci, var den stolta ägaren till sin fars verksamhet och en enorm ...
Nästan alla europeiska länder i olika stadier av sin utveckling försökte öka sin makt och välstånd, ...

Efter att ha förlorat sina amerikanska kolonier, fördrivna från Indien, belönade Frankrike sig själv genom att erövra stora territorier i ...

Kurder är världens största nation utan stat. Samtidigt finns det praktiskt taget ingenting för en vanlig man på gatan ...

Francesco (16.I.1836 - 28.XII.1894) - King of the Two Sicilies (1859-60), en representant för dynastin ...
Vi fortsätter miniatyrcykeln om Europas huvudstäder på 16-19-talet. Låt oss prata om London idag. Mer exakt, naturligtvis först ...

Cellulosa - vad är det? Denna fråga oroar alla som är associerade med organisk kemi. Låt oss försöka ta reda på ...

När 1870 en självlärd arkeolog, beslutsam drömmare och framgångsrik affärsman Heinrich Schliemann upptäckte ...

Dolphin är en av de mest mystiska och intressanta däggdjur som lever på vår planet. Sedan antiken ...
Inert substans är en uppsättning av dessa ämnen i biosfären, i vilken bildande levande organismer inte deltar. [...
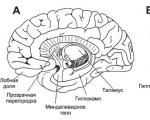
Integrativa funktioner förstås som den analytiskt-syntetiska aktiviteten hos hjärnbarken och många ...

Silhuetter av Pushkin-eran. - M .: Agraf, 1999. - 320 s. - (Litterär workshop). - S. 37-42. Altabaeva E ....
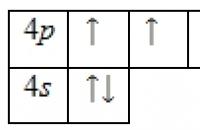
Tenn är ett kemiskt grundämne med symbolen Sn (från latin: stannum) och atomnummer 50. Det är en post-övergång ...